
記事の概要
この記事では、PythonのFastAPIライブラリを使って、Dockerコンテナで動作するWebAPIの開発環境の構築から開発、実行までの流れを紹介します。
この記事を参考に、WebAPI開発のスタートの一助となれば幸いです。
今回の記事の対象者
この記事は次のような方に向けています:
- Pythonで簡単にWebAPIを開発したい方
- Dockerコンテナを使ってサーバー(VPSやクラウド環境)を環境を統一したい方
- ドメイン駆動設計に興味がある方
はじめに
普段は、Java使ってWebアプリやバックエンドのWebAPIの開発を行っていますが、もっと手軽なPythonとFastAPIを使ってアプリが作ってみたくなりました。
FastAPIは、WebアプリやWebAPIをつくるためのPythonのライブラリです。
FastAPIが特にすごいのは、その速さと簡単さです。名前の通り「速い(Fast)」のが特徴で、コードを書く人が少ない労力で効率的に動くプログラムを作れるように設計されています。また、Pythonの他のフレームワークと比べて、エラーが出にくいように工夫されているので、プログラミング初心者でも安心して使えるのも魅力です。
FastAPIについての詳細は、公式サイトをご覧下さい。
以前からドメイン駆動設計を適用した、拡張性や可読性が高いプログラムコードにも関心がありました。元々、Pythonはシンプルで保守性の高いコードを書くことが出来ますが、ドメイン駆動設計を用いることで、更に拡張性や保守性が高くなるのではと今回適用してみました。
目次
コンセプト
まずは、本記事で構築する開発環境やアプリのコンセプトを紹介していきます。
- Fast APIプロジェクト※: FastAPIを使ったディレクトリ構造やファイルの役割を理解し、効率的にプロジェクトを管理します。※アプリを開発するためのファイルやフォルダの集まり。
- WebAPI開発: Fast APIを使ってWebAPIを作成し、他のシステムやクライアントとデータをやり取りする。
- ビルドと依存関係管理: Poetryを使ってプロジェクトのライブラリと依存関係を管理する。
- コンテナ技術: DockerコンテナとDocker Composeを使って、アプリをコンテナ化し、開発および本番環境の差異をなくす。
開発環境
- Fast APIアプリ開発の操作をPyCharmで実施出来るようにする
- ソースコードはすべてのプラットフォームで共通とする
- WebAPIの設定は、クラウドやVPSにデプロイ出来る様にDockerコンテナを利用する
開発するWebAPIの概要
- ニュースのヘッドライン情報を収集しデータベースに格納し、リクエストに応じてデータを取得します。このWebAPIを、以降は「ニュースアグリゲーターAPI」と呼びます。
- 今までは色々なサイトを回ってニュースを集めて大変だった事を、「ニュースアグリゲーターAPI」にお任せしてしまおう!というイメージです。
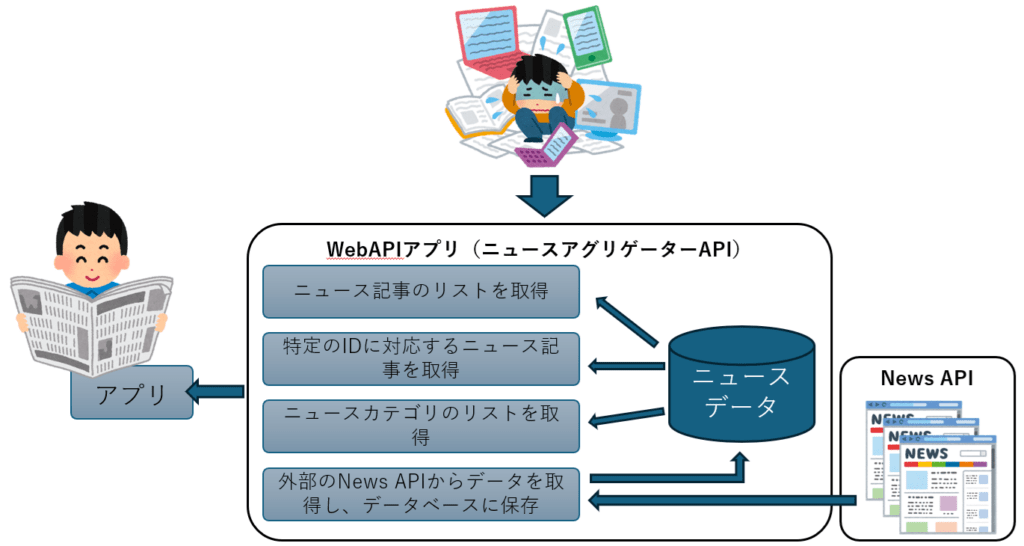
- オープンなNews APIを使用します。開発に当たっては、事前に登録とAPI Keyを発行しておいてください。News APIについては、次項で概要を紹介します。
- ニュースアグリゲーターAPIのエンドポイント示します。
| HTTPメソッド, URL | 説明 |
|---|---|
| GET, /news/ | ニュース記事のリストを取得します。カテゴリでフィルタリング可能。 パラメーター skip (int, オプション) – スキップするレコードの数<br>limit (int, オプション) – 取得するレコードの上限数<br>category (str, オプション) – カテゴリでフィルタリング |
| GET, /news/{article_id} | 特定のIDに対応するニュース記事を取得します。 パラメーター article_id (int) – ニュース記事のID |
| POST, /news/fetch | 外部のニュースソースからデータを取得し、データベースに保存します。 パラメーター なし |
| GET, /categories/ | ニュースカテゴリのリストを取得します。 パラメーター なし |
News APIの概要
News APIは、ニュース記事をプログラム的に取得するためのWeb APIです。このAPIを利用することで、さまざまなニュースソースやブログから最新のニュース記事を簡単に収集できます。
主な特徴
- 多様なニュースソース: News APIは、数千のニュースソースやブログから記事を提供しており、国際的なニュースから特定のトピックに特化した記事まで幅広くカバーしています。
- リアルタイムでのニュース取得: 最新のニュース記事をリアルタイムで取得することができます。
- クエリによる絞り込み: 特定のキーワード、ニュースソース、国、言語、カテゴリーなどで記事を絞り込むことが可能です。
利用料金
- News APIは無料プランも提供しており、一定のリクエスト数まで無料で利用できます。ただし、商用利用や高頻度のリクエストには有料プランが必要です。
News APIの詳細は、公式サイトをご覧下さい。
ソフトウェア・ハードウェア
必要なツール、ライブラリ、端末は以下の通りです。
開発ツール
以下、開発ツールとその公式サイトの一覧です。公式サイトを参照して事前に導入をしておいてください。
| ツール名 | 用途 |
|---|---|
| PyCharm | 開発全般 |
| Poetry | Pythonパッケージ管理 |
| Docker Desktop | Webアプリ開発 |
ライブラリ
以下は、ニュースアグリゲーターAPIを構成する主要なソフトウェアとその解説です。導入は、記事本編の中で解説します。
| ライブラリ | 説明 |
|---|---|
| Python 3.12 | 汎用プログラミングのための高水準プログラミング言語。 |
| fastapi 0.112.0 | Python製の高速なWebフレームワーク。APIの作成を迅速に行うためのツール。 |
| uvicorn 0.30.5 | ASGIフレームワーク向けの高速なWebサーバー。FastAPIアプリケーションを実行するために使用。 |
| sqlalchemy 2.0.32 | データベースの操作を簡単に行うためのORM(オブジェクトリレーショナルマッピング)ライブラリ。 |
| psycopg2-binary 2.9.9 | PostgreSQLデータベースとPythonを接続するためのライブラリ。 |
| aiohttp 3.10.3 | 非同期HTTPクライアントライブラリ。外部のニュースAPIからデータを非同期で取得するために使用。 |
| pydantic 2.8.2 | データ検証と設定管理のためのライブラリ。FastAPIと組み合わせてデータモデルのバリデーションを行う。 |
| pydantic-settings 2.4.0 | 環境変数や設定ファイルから設定を読み込むための拡張ライブラリ。 |
| python-dotenv 1.0.1 | .envファイルから環境変数を読み込むためのライブラリ。 |
端末
以下、今回の環境を構築する対象の端末スペックです。
| 項目 | 詳細 |
|---|---|
| ハードウェア | Apple Silicon M3, RAM 24GB |
| OS | macOS Sonoma 14.5 |
本記事で紹介するソフトウェアおよびツールは、筆者の個人的な使用経験に基づくものであり、公式のサポート外の設定や使用方法を含む場合があります。利用に際しては、公式サイトの指示およびガイドラインを参照し、自己責任で行ってください。
プロジェクトの準備
プロジェクトディレクトリ構造
ディレクトリ構造(最終イメージ)を以下に示します。
news_aggregator/
├── app/
│ ├── __init__.py
│ ├── config.py
│ ├── main.py
│ ├── models.py
│ ├── repository.py
│ ├── services.py
│ ├── schemas.py
│ ├── routers/
│ │ ├── __init__.py
│ │ ├── news.py
│ │ └── categories.py
├── .env
├── docker-compose.yml
├── Dockerfile
├── pyproject.toml
└── README.md
主な、ソースコードがそれぞれどのような役割を担っているか、イメージを以下に示します。
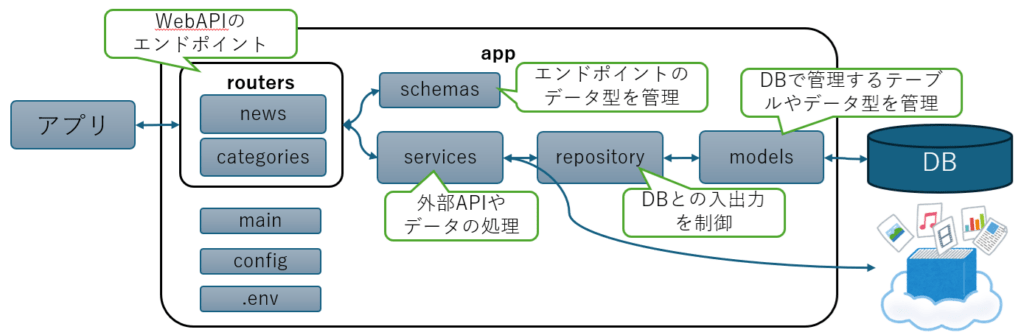
【筆者の一言】
今回外部APIであるNews APIからの情報取得とデータベースへの格納は、非同期処理を使って高速化を図っています。非同期処理は高速化でよく使うテクニックなので、今からでも少しずつ慣れておくと将来便利なテクニックですのでお薦めです。
Poetryのインストール
Pythonライブラリ管理ツールをインストールします。
Poetryがインストールされていない場合は、以下のコマンドでインストールします。
curl -sSL <https://install.python-poetry.org> | python3 -
Poertyのパスを環境変数に追加します。
export PATH="/Users/xxxxxxx/.local/bin:$PATH"
Docker Desktopのインストールは以下の記事を参考にしてください。
プロジェクトのセットアップ
新しいプロジェクトディレクトリ(news_aggregator)を作成します。このディレクトリにすべてのコードや設定ファイルが格納されます。
mkdir news_aggregator
cd news_aggregator
プロジェクトディレクトリ(news_aggregator)で以下のコマンドを実行してPoetryプロジェクトを初期化します。
poetry init --no-interaction
–no-interactionフラグを使うことで、対話的なセットアップをスキップできます。
初期化が終了すると、pyproject.tomlファイルが生成されます。
pyproject.toml
[tool.poetry]
name = "news-aggregator"
version = "0.1.0"
description = ""
authors = ["Your Name <you@example.com>"]
readme = "README.md"
[tool.poetry.dependencies]
python = "^3.12"
[build-system]
requires = ["poetry-core"] build-backend = "poetry.core.masonry.api"必要なライブラリのインストール
アプリ開発に必要なライブラリをPoetryを使って追加します。
今回は、fastapi、uvicorn、sqlalchemy等を使うので、以下のコマンドを実行します。
poetry add fastapi uvicorn sqlalchemy psycopg2-binary aiohttp pydantic pydantic-settings python-dotenv
ライブラリの追加が完了するとpoetry.lockファイルが生成されます。
pyproject.tomlファイルに依存関係が追加されます。
poetry.lockには、追加されたライブラリのバージョン管理情報が追加されます。
以下は、コマンドを実行した際に出力されるメッセージのサンプルです。指定したライブラリの依存関係を解決しつつ、各ライブラリの構成とバージョンが確定されているのが分かります。
(base) xxxxxx@xxxxx news_aggregator % poetry add fastapi uvicorn sqlalchemy psycopg aiohttp pydantic python-dotenv
Using version ^0.112.0 for fastapi
Using version ^0.30.5 for uvicorn
Using version ^2.0.32 for sqlalchemy
Using version ^3.2.1 for psycopg
Using version ^3.10.3 for aiohttp
Using version ^2.8.2 for pydantic
Using version ^1.0.1 for python-dotenv
Updating dependencies
Resolving dependencies... (2.6s)
Package operations: 22 installs, 0 updates, 0 removals
- Installing idna (3.7)
- Installing sniffio (1.3.1)
- Installing typing-extensions (4.12.2)
- Installing annotated-types (0.7.0)
- Installing anyio (4.4.0)
- Installing frozenlist (1.4.1)
- Installing multidict (6.0.5)
- Installing pydantic-core (2.20.1)
- Installing aiohappyeyeballs (2.3.5)
- Installing aiosignal (1.3.1)
- Installing attrs (24.2.0)
- Installing click (8.1.7)
- Installing h11 (0.14.0)
- Installing pydantic (2.8.2)
- Installing starlette (0.37.2)
- Installing yarl (1.9.4)
- Installing aiohttp (3.10.3)
- Installing fastapi (0.112.0)
- Installing psycopg (3.2.1)
- Installing python-dotenv (1.0.1)
- Installing sqlalchemy (2.0.32)
- Installing uvicorn (0.30.5)
Writing lock filepyproject.toml
[tool.poetry]
name = "news-aggregator"
version = "0.1.0"
description = ""
authors = ["Your Name <you@example.com>"]
readme = "README.md"
[tool.poetry.dependencies]
python = "^3.12" fastapi = "^0.112.0" uvicorn = "^0.30.5" sqlalchemy = "^2.0.32" aiohttp = "^3.10.3" pydantic = "^2.8.2" python-dotenv = "^1.0.1" pydantic-settings = "^2.4.0" psycopg2-binary = "^2.9.9"
[build-system]
requires = ["poetry-core"] build-backend = "poetry.core.masonry.api"poetry.lock
生成されたpoetry.lockファイルの一部を以下に抜粋します。かなり詳細な管理情報が記載されています。このファイルを用いることで、どの環境でも厳密に同じライブラリ構成で環境を再現することが出来ます。
# This file is automatically @generated by Poetry 1.8.3 and should not be change
d by hand.
[[package]]
name = "aiohappyeyeballs"
version = "2.3.5"
description = "Happy Eyeballs for asyncio"
optional = false
python-versions = ">=3.8"
files = [
{file = "aiohappyeyeballs-2.3.5-py3-none-any.whl", hash = "sha256:4d6dea5921
5537dbc746e93e779caea8178c866856a721c9c660d7a5a7b8be03"},
{file = "aiohappyeyeballs-2.3.5.tar.gz", hash = "sha256:6fa48b9f1317254f122a
07a131a86b71ca6946ca989ce6326fff54a99a920105"},
]
[[package]]
name = "aiohttp"
version = "3.10.3"
description = "Async http client/server framework (asyncio)"
optional = false
python-versions = ">=3.8"
ニュースアグリゲーターAPIの開発
環境変数
.env
このファイルに、APIキーとデータベースの接続情報を保存します。これで、ソースコードに直接機密情報を書かなくて済みます。
NEWS_API_KEY=your_actual_api_key_here
POSTGRES_USER=user
POSTGRES_PASSWORD=password
POSTGRES_DB=news_aggregator_db
.envファイルは環境ごとに異なる設定を保存するために使います。ここに保存された情報は、他のプログラムからも安全に利用できるようになります。
app/config.py
アプリケーションで使う設定をまとめます。特に、環境変数からAPIキーやデータベース接続情報を読み込みます。
from pydantic_settings import BaseSettings
from dotenv import load_dotenv
import os
# .env ファイルから環境変数をロード
load_dotenv()
class Settings(BaseSettings):
db_user: str = os.getenv("POSTGRES_USER")
db_password: str = os.getenv("POSTGRES_PASSWORD")
db_name: str = os.getenv("POSTGRES_DB")
db_host: str = "db" # Docker Composeで定義したサービス名
db_url: str = f"postgresql://{db_user}:{db_password}@{db_host}/{db_name}"
news_api_key: str = os.getenv("NEWS_API_KEY") # 環境変数からAPIキーを取得
settings = Settings()
このコードは、環境変数に保存された情報を使って、アプリケーションがデータベースやAPIにアクセスできるように設定します。
app/models.py
ニュース記事やカテゴリのデータの形(モデル)を定義します。これらのデータは、データベースに保存されます。
from sqlalchemy import Column, Integer, String, TIMESTAMP
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Article(Base):
__tablename__ = "articles"
id = Column(Integer, primary_key=True, index=True)
title = Column(String, index=True)
description = Column(String)
content = Column(String)
url = Column(String, unique=True, index=True)
category = Column(String, index=True)
published_at = Column(TIMESTAMP)
created_at = Column(TIMESTAMP)
updated_at = Column(TIMESTAMP)
class Category(Base):
__tablename__ = "categories"
id = Column(Integer, primary_key=True, index=True)
name = Column(String, unique=True)
このコードは、ニュース記事やカテゴリのデータがどのようにデータベースに保存されるかを決めています。
app/repository.py
データベースにデータを保存したり、読み出したりするためのコードです。
from sqlalchemy.orm import Session
from app.models import Article, Category
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from app.config import settings
# データベース接続エンジンの作成
engine = create_engine(settings.db_url)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
class ArticleRepository:
def __init__(self, db: Session):
self.db = db
def get_all(self, skip: int = 0, limit: int = 10):
return self.db.query(Article).offset(skip).limit(limit).all()
def get_by_id(self, article_id: int):
return self.db.query(Article).filter(Article.id == article_id).first()
def get_by_category(self, category_name: str, skip: int = 0, limit: int = 10):
return self.db.query(Article).filter(Article.category == category_name).offset(skip).limit(limit).all()
def create(self, article: Article):
self.db.add(article)
self.db.commit()
self.db.refresh(article)
return article
class CategoryRepository:
def __init__(self, db: Session):
self.db = db
def get_all(self):
return self.db.query(Category).all()
def create(self, category: Category):
self.db.add(category)
self.db.commit()
self.db.refresh(category)
return category
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
このコードは、データベースとのやり取りを管理し、必要なデータを保存したり、読み込んだりします。
app/services.py
ニュースを非同期で取得し、データベースに保存するためのコードです。
from app.models import Article
from app.repository import ArticleRepository, CategoryRepository
from sqlalchemy.orm import Session
import aiohttp
import asyncio
from app.config import settings
class NewsService:
def __init__(self, db: Session):
self.article_repository = ArticleRepository(db)
self.category_repository = CategoryRepository(db)
async def fetch_and_store_news(self, url: str, category_name: str):
async with aiohttp.ClientSession() as session:
async with session.get(url, params={"apiKey": settings.news_api_key}) as response:
data = await response.json()
articles = [
Article(
title=item["title"],
description=item["description"],
content=item["content"],
url=item["url"],
category=category_name,
published_at=item["publishedAt"]
) for item in data["articles"]
]
for article in articles:
self.article_repository.create(article)
async def fetch_multiple_sources(self):
urls = [
"<https://newsapi.org/v2/top-headlines?country=us>",
"<https://newsapi.org/v2/top-headlines?country=jp>"
]
tasks = [self.fetch_and_store_news(url, "general") for url in urls]
await asyncio.gather(*tasks)
def list_articles(self, category: str = None, skip: int = 0, limit: int = 10):
if category:
return self.article_repository.get_by_category(category, skip, limit)
return self.article_repository.get_all(skip, limit)
def list_categories(self):
return self.category_repository.get_all()
def get_by_id(self, article_id: int):
"""
指定されたIDに対応するニュース記事を取得します。
"""
return self.article_repository.get_by_id(article_id)
このコードは、外部のニュースソースからデータを取得し、それをデータベースに保存する機能を提供します。
app/schemas.py
データの構造を定義します。これにより、APIの応答が一定の形式になります。
from pydantic import BaseModel
from typing import Optional
from datetime import datetime
class ArticleSchema(BaseModel):
id: Optional[int]
title: str
description: Optional[str]
content: Optional[str]
url: str
category: str
published_at: datetime
class Config:
orm_mode = True
class CategorySchema(BaseModel):
id: Optional[int]
name: str
class Config:
orm_mode = True
このコードは、APIを通じてやり取りされるデータがどのような形をしているかを定義します。
app/routers/news.py
ニュース記事に関連するAPIエンドポイント(アクセスするためのURL)を定義します。
from fastapi import APIRouter, Depends, HTTPException
from sqlalchemy.orm import Session
from app.repository import get_db
from app.services import NewsService
from app.schemas import ArticleSchema
from typing import List
router = APIRouter(prefix="/news", tags=["news"])
@router.get("/", response_model=List[ArticleSchema])
def list_news(skip: int = 0, limit: int = 10, category: str = None, db: Session = Depends(get_db)):
service = NewsService(db)
return service.list_articles(category, skip, limit)
@router.get("/{article_id}", response_model=ArticleSchema)
def get_news(article_id: int, db: Session = Depends(get_db)):
service = NewsService(db)
article = service.get_by_id(article_id)
if not article:
raise HTTPException(status_code=404, detail="Article not found")
return article
@router.post("/fetch")
async def fetch_news(db: Session = Depends(get_db)):
service = NewsService(db)
await service.fetch_multiple_sources()
return {"status": "success"}
このコードは、ニュース記事に関連する操作(ニュースの取得やリスト表示)をAPI経由で行うための設定を行っています。
app/routers/categories.py
カテゴリに関連するAPIエンドポイントを定義します。
from fastapi import APIRouter, Depends
from sqlalchemy.orm import Session
from app.repository import get_db
from app.services import NewsService
from app.schemas import CategorySchema
from typing import List
router = APIRouter(prefix="/categories", tags=["categories"])
@router.get("/", response_model=List[CategorySchema])
def list_categories(db: Session = Depends(get_db)):
service = NewsService(db)
return service.list_categories()
app/main.py
アプリケーション全体を設定するファイルです。ここでは、アプリケーションの中心部分を作ります。
from fastapi import FastAPI
from app.routers import news, categories
app = FastAPI()
app.include_router(news.router)
app.include_router(categories.router)
このコードでは、ニュースやカテゴリに関連する部分をアプリケーションに組み込んでいます。
Dockerの設定
Dockerfile
アプリケーションのコンテナを構築するための設定ファイルです。
FROM python:3.12-slim
WORKDIR /app
COPY pyproject.toml poetry.lock ./
RUN pip install poetry && poetry install --no-dev
COPY . .
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000", "--reload"]
docker-compose.yml
Docker Composeを使って、アプリケーションとデータベースの環境を設定します。
services:
db:
image: postgres:latest
environment:
POSTGRES_USER: ${POSTGRES_USER}
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD}
POSTGRES_DB: ${POSTGRES_DB}
volumes:
- postgres_data:/var/lib/postgresql/data
ports:
- "5432:5432"
app:
build: .
command: uvicorn app.main:app --host 0.0.0.0 --port 8000 --reload
volumes:
- .:/app
ports:
- "8000:8000"
depends_on:
- db
env_file:
- .env # .envファイルを指定
volumes:
postgres_data:
データベースマイグレーションスクリプトの準備
マイグレーションスクリプトを実行するためのPythonスクリプト(例: init_db.py)が既に用意されているものとします。スクリプトは、news_aggregatorディレクトリの直下に置かれています。
# init_db.py
from app.models import Base
from app.repository import engine
def init_db():
Base.metadata.create_all(bind=engine)
if __name__ == "__main__":
init_db()
Docker Composeでコンテナを起動する
Docker Composeを使用してアプリケーションとデータベースのコンテナを起動します。これにより、データベースが利用可能な状態になります。
docker compose up -d
コンテナ内でマイグレーションスクリプトを実行
次に、Dockerコンテナ内でこのマイグレーションスクリプトを実行します。
まず、アプリケーションが動作しているコンテナにアクセスします。docker-compose execコマンドを使います。
docker compose exec app bash
マイグレーションスクリプトの実行
コンテナ内で、以下のコマンドを実行してマイグレーションスクリプトを実行します。
python init_db.py
コンテナから退出
マイグレーションが完了したら、コンテナから退出します。
exit
Docker Composeでアプリケーションを起動
アプリケーションを起動します。以下のコマンドを実行してください。
docker-compose up --build
APIのテスト
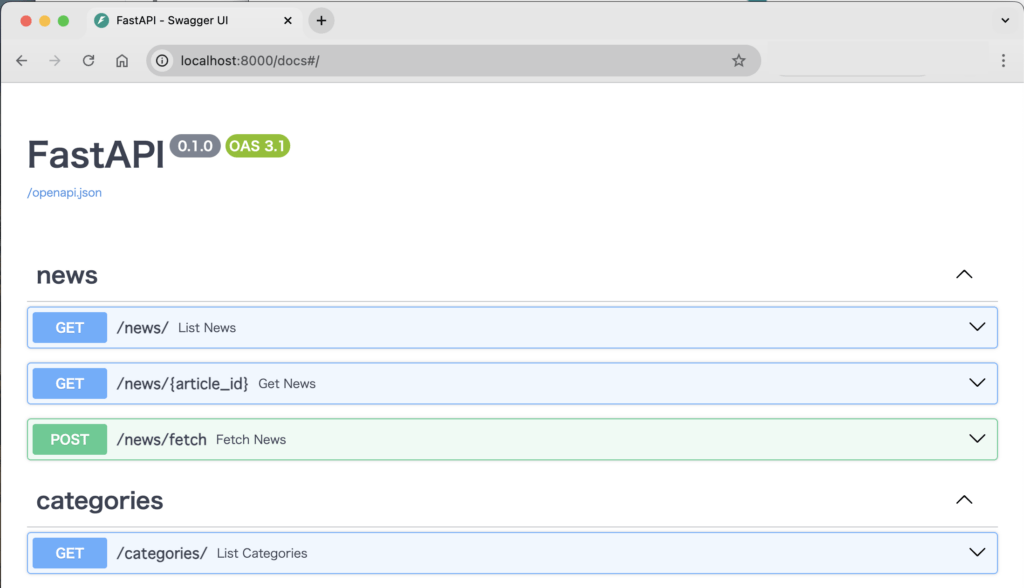
ブラウザで次のURLにアクセスし、APIが動作していることを確認します:
• Swagger UI: http://localhost:8000/docs で、APIの操作とテストができます。
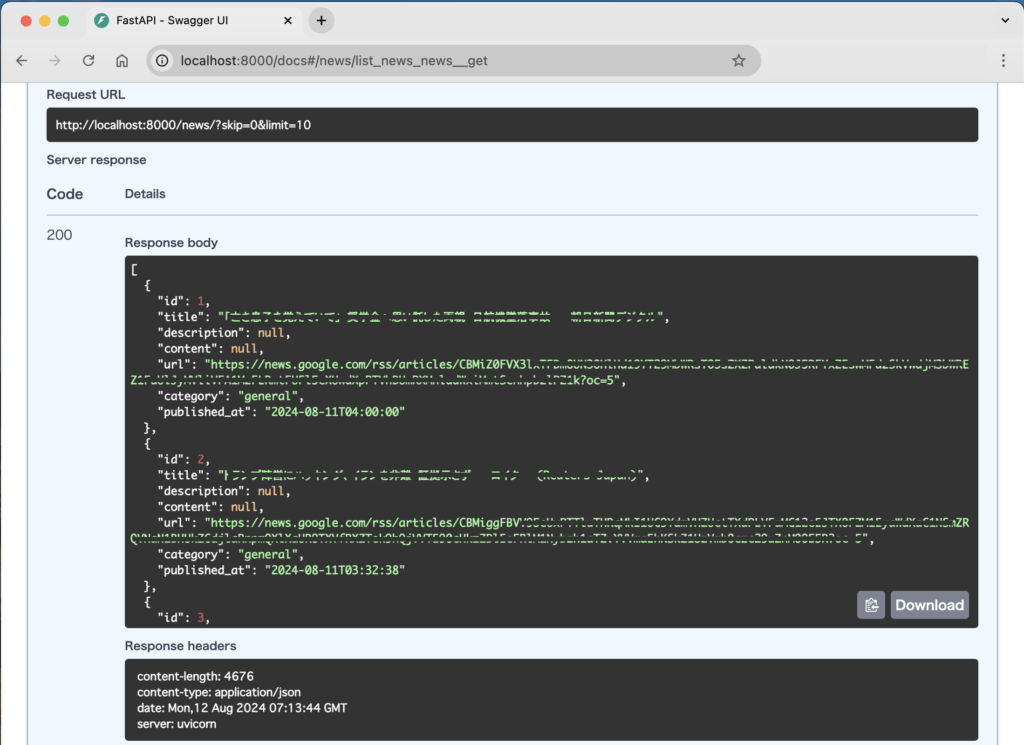
• ニュース取得: http://localhost:8000/news/fetch にアクセスし、ニュースを取得します。
これらのURLにアクセスすることで、ニュースを収集し、それを表示することができます。
README.md
プロジェクトの概要と使い方を説明するファイルです。
# News Aggregator API
This is a news aggregator API built with FastAPI, using Domain-Driven Design principles. It collects news articles from various sources and categorizes them.
## Features
- Fetch and store news articles from external sources.
- List articles by category.
- List all available categories.
## Requirements
- Python 3.12
- Docker
- Docker Compose
- Poetry
## Setup
1. Clone the repository.
2. Run `poetry install` to install dependencies.
3. Set up the database:
```bash
docker-compose up --build
```
4
まとめ
これで、Python 3.12とFast APIを使用したニュースアグリゲーターAPIのすべての手順と成果物が揃いました。
データベースのマイグレーションスクリプトの実行方法も含めて、この手順に従ってプロジェクトを進めることで、ニュースを効率的に収集し、管理し、APIを通じて取得するアプリケーションを作成できます。




